

A couple of weeks back, I was doing some research on some old mergers and acquisitions in the data security market when I found myself drawing a blank on the name of a startup that was purchased a while back. Online search was no help because I didn’t have any differentiating search terms that I could use. So, I thought I’d try ChatGPT. I dutifully provided the little bits and pieces of information I knew in the form of a question, and to my surprise ChatGPT was able to find the name of the company on the first try. What would have taken me hours of scanning through search results was done in minutes by generative AI, and this example serves well to demonstrate the potential of this technology to change the way we do just about everything.
It makes sense, then, that many businesses are actively looking at GenAI as a transformative technology that will allow them to extract enormous value from the large sets of proprietary data they possess. At the same time, the information security teams for those businesses are raising concerns about the data security and compliance risks of using private and regulated data. In fact, many companies have outright disallowed the use of any public GenAI services (such as ChatGPT) because of these risks. To mitigate the security and compliance concerns, businesses are considering retrieval-augmented generation (RAG) to take advantage of the capabilities of a large language model (LLM) while retaining control of their data.
RAG combines generative models with information retrieval systems to deliver highly context-aware and accurate content. More importantly, it doesn’t require companies to surrender large quantities of their sensitive data to a 3rd party for fine-tuning of an LLM because it can make use of existing data without additional data sanitization and labeling. It also has relatively modest computational and storage requirements that allow companies to run the system within existing IT or cloud infrastructure using open-source LLMs. At first glance, being able to own the infrastructure appears to address any security or compliance concerns.
With GenAI, however, controlling the system that runs it is not the same as maintaining control of the data (or the output). Whereas legacy information systems had well-defined and deterministic access controls, GenAI systems can be coaxed into revealing sensitive or protected information by simply altering the prompt. To prove this point, ask your database or file system administrators to generate a report on permissions on the various data assets, and they will be able to send you a clear list of who has access to which database tables or files. Likewise, if you ask a GenAI administrator to produce the same report, you will likely get blank stares. For Information Security teams everywhere, this lack of accountability and control over data is the very opposite of what almost every compliance requirement requires.
Fortunately, all is not lost, and in this blog post, we will discuss a way to secure data used for RAG and regain control over data access to ensure compliance. Only by ensuring the safe usage of sensitive data can enterprises truly unlock the potential of GenAI for their applications without taking on undue risks of data exposure or breaches.
Introduction to RAG
Before getting into how to secure RAG, let’s briefly cover what RAG is and how it differs from other approaches of using LLMs. When you use ChatGPT or other GenAI services today, you are directly giving a prompt to an LLM that will generate a response based on the prompt. Typically, these public GenAI services have been trained on public data from the Internet, so their responses are limited by the training set.
With RAG, you add components to intercept your prompt and attach context to it before soliciting a response from the LLM. The context is typically private or sensitive data that would not have been part of the training dataset for the LLM.
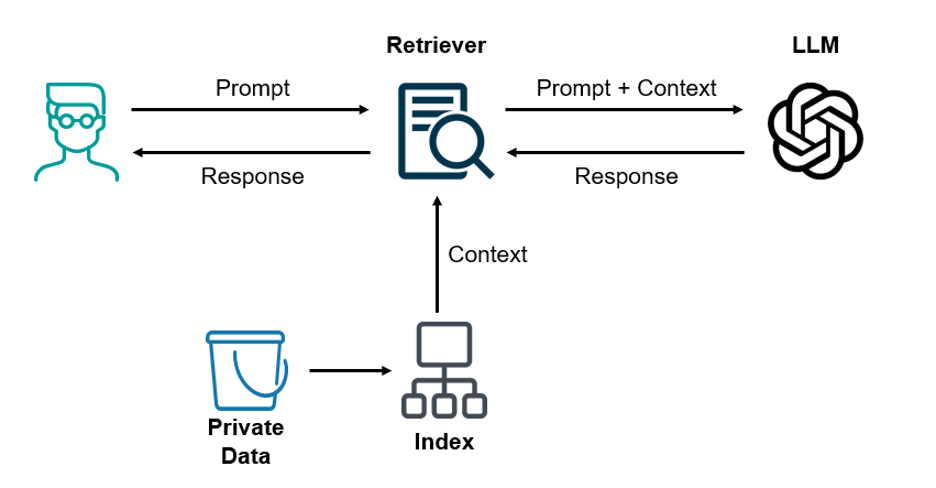
In essence, RAG allows you to leverage an LLM’s understanding of language to search through your own data set to find answers to your question. This is done through the use of a “Retriever” that searches through an indexed version of your data set and extracts out the most relevant information to include as the context to send to the LLM along with the prompt.
As mentioned previously, even with RAG, a myriad of security and compliance issues exist. Right away, the migration of private data to an index used by the retriever should give any InfoSec team pause. Administrators of the data store used for the index should not have direct access to any of the sensitive or regulated data, yet current implementations of those data stores offer, at best, data at rest encryption that gives any privileged users of those systems the ability to extract data.
Furthermore, there’s little or no access control being enforced on the response given back to the original user. Different users with different roles will need to use the RAG application. If these users accessed the data set through the original data stores, access controls at each of the data stores could have limited the types of data that the users would have access to. Now that data from the various data stores have been commingled and indexed, there’s no way to enforce the same access controls. This problem is further exacerbated by the way GenAI formulate responses on a token by token (or word by word) basis effectively requiring access control decisions to be made for each token as it’s included in each response. Plus there is the risk of hallucination with GenAI applications, which might cause InfoSec to worry that private data did get leaked.
Implementing Data Security with RAGs
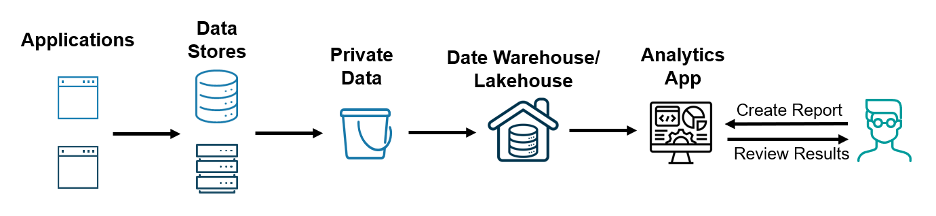
While the compliance problems for GenAI seem daunting, there is a very practical approach to securing the sensitive data values, and the approach draws its roots from security data for analytics. If we take a step back and look at the full RAG pipeline from a different angle, we can see that it looks similar to data pipelines that many enterprises already have. In fact, one can argue that RAG is a new variation or an extension of a data pipeline where the data warehouse/lakehouse is replaced with a document index document store and the analytics application replaced with a retriever and LLM.
RAG Pipeline:
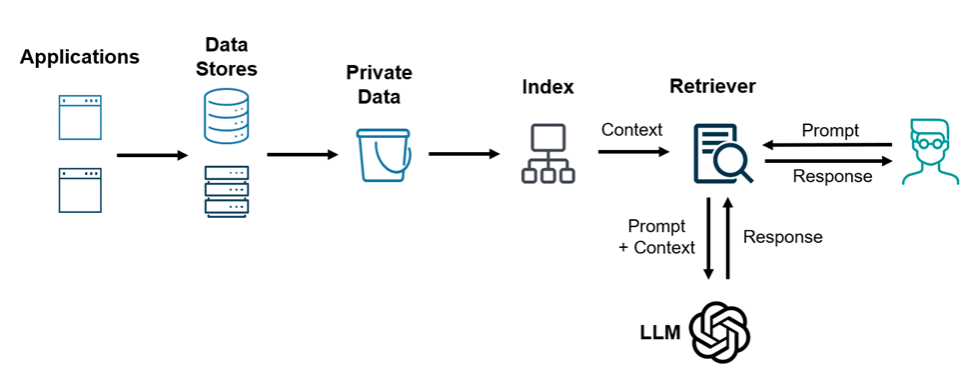
Like RAG, and GenAI in general, data analytics faces both a privileged user problem and an access control problem due to the aggregation of data from different sources into a single system. The solution to these problems with analytics is to ensure that the data is encrypted at a field level (for example, with an inline encryption proxy) before it is stored in the aggregated data repository. This can be done because there’s much more context about the data at its source for deciding whether or not it requires encryption. Securing the data at the source means the data is protected regardless of where it flows, whether to other applications or analytics projects (this is known as data-centric protection). By encrypting at the source (or the earliest possible stage in the pipeline), there is more certainty that the correct subset of data values is protected.
Once encrypted, the data can move downstream without risk of compromise. When the protected data is accessed from either the analytics app or RAG system, a decryption proxy can be used to decrypt the data on behalf of the user, provided the user has been granted access (RBAC). In this case, the proxy provides a very granular form of access control that can give the end user direct access or masked version of the value based on their permissions or roles.
One potential drawback of encrypting data at a field-level early in the pipeline is that it may affect the results (the utility of the data). However, it’s important to note that nearly all compliance regulations focus on PII and other data values that typically do not or should not be processed. Even if some of the responses from the RAG applications are affected, protecting the subset of regulated data so that it is never exposed ensures compliance requirements are met while still enabling use of private data for most RAG use cases. This achieves the best balance of data security with the utility.
There is no doubt that RAG holds immense promise for revolutionizing content creation and personalization across various domains for businesses that want to make use of their own private dataset in addition to the public data that the LLMs were trained on. However, data security and compliance remain a central concern and must be addressed for any InfoSec team to greenlight projects that make use of regulated data.
The most practical approach to solving this problem is similar to the approach that should be used to secure regulated data in other enterprise data pipelines. Namely, encrypt the data at a field-level as early as possible, and decrypt the data only for allowed users based on role-based access control (RBAC) policies. Baffle provides the easiest way to implement such a data-centric solution by using encryption proxies that implement field-level encryption and RBAC without application changes. This unique, no-code, approach can greatly accelerate your GenAI and data analytics projects by addressing compliance concerns. For more information about how Baffle can help your genAI project, please visit our website where you will be able to schedule a meeting with a Baffle expert.




Join our newsletter
Schedule a Demo with the Baffle team
Meet with Baffle team to ask questions and find out how Baffle can protect your sensitive data.

Easy
No application code modification required

Fast
Deploy in hours not weeks

Comprehensive
One solution for masking, tokenization, and encryption

Secure
AES cryptographic protection

Flexible
No impact to user experience