Data De-Identification
Data de-identification is the process used to prevent a person’s identity or private information in a database from being revealed. Processes include masking personal identifiers or replacing real information with temporary data. Often, de-identified data is put through a process of re-identification for further use.
De-identification is part of the overall practice of loss prevention and data containment and is used in nearly every industry to protect consumer data and provide adherence to protected health information such as the HIPAA (Health Insurance Portability and Accountability Act) and many other privacy acts or use cases.
The De-Identification Process and the Cloud
Enterprise data growth has continued exponentially, and the migration to cloud data lakes has become a major trend, allowing big data environments to expand flexibly and without limit. As more organizations use cloud data lakes for business analytics, machine learning, and artificial intelligence, specific data privacy protection challenges are emerging.
The explosion of data has led to another trend – the inadvertent exposure or misconfiguration of data elements in some cloud-based environments. There is an obvious need to de-identify the underlying data or the original data inside cloud data lakes, while still permitting the business to take advantage of big data technologies such as analytics and AI modeling.
In the cloud providers’ “shared responsibility model”, the provider is responsible for providing security of the underlying infrastructure and the data centers, while the customer is responsible for the data put into the cloud. So de-identification means de-identifying the actual data values or protecting the underlying data values that are being put in.
Unfortunately, many de-identification techniques require additional development or altering the data pipeline, and as a result either slow down the use of cloud-based analytics or leave de-identified data sets potentially exposed. Further, de-identification represents only part of the challenge as new methods to access and warehouse data can limit scenarios where authorized re-identification or analysis of data may be required.
Common Methods for Data De-Identification
- Data-centric encryption, including field-level encryption / record-level encryption - actually protecting specific data values with some forms of encryption.
- Data tokenization, which made use of a tokenization library, or tokenization, or what is known as a boltless tokenization, or some type of codebook method – for example, methods of replacing an account number with another value.
- Format-preserving encryption - another variant of a data type and length-preserving encryption mode. Data such as social security numbers, medical record numbers, credit card numbers, or email addresses would then be preserved from a formatting perspective but randomized in terms of the actual underlying data values.
- Data masking - used for controlling the presentation layer, so instead of seeing somebody’s full credit card number, you might only see the last four digits, or values can be completely obfuscated.
- Role-based data masking – allows certain roles within an organization or certain parties that are in a more privileged state or third parties that may be external, but basically, get presented with different views of the data that is dynamically rendered based on your group membership.
- Advanced Encryption schemes – includes enclave-based encryption, where data is secured much like the fingerprint or face ID on a mobile device, extended to a server-class compute mode, homomorphic encryption, and multi-party computation.
Baffle’s Data Protection Services allows for easy de-identification of data on-the-fly and selective re-identification of data based on authorized roles via a no-code model.
Benefits of Objects Encryption vs. Data-Centric Encryption
- De-identify, tokenize or encrypt data INSIDE objects and files.
- Safe harbor from accidental data leaks from key privacy and compliance regulations.
- Accelerate cloud-based data analytics programs by addressing key security and privacy concerns.
Baffle allows you to push data to the cloud on a continual basis, de-identify it on the fly, and then allow members of your organization to run the types of analytics that they would need to run on that respective data set to minimize re-identification risks:
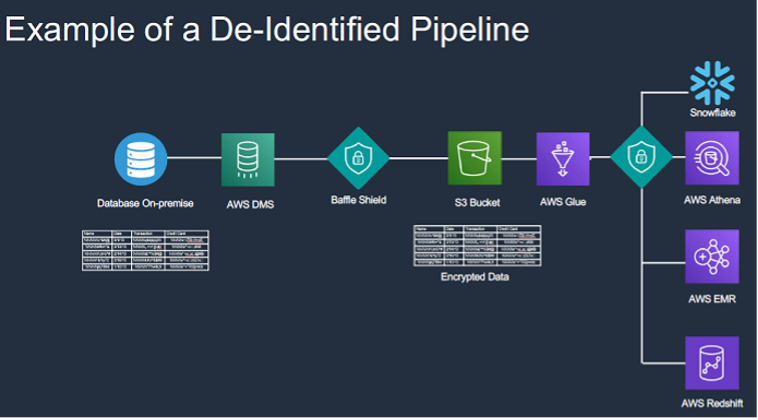 Cloud data lakes give organizations a lot more flexibility to accommodate massive data growth for the future. The risk of data breaches continues to be with us but, companies can leverage data-centric protection methods and Baffle’s solution to reduce your risk, unlock the value in the data and help to monetize it.
Cloud data lakes give organizations a lot more flexibility to accommodate massive data growth for the future. The risk of data breaches continues to be with us but, companies can leverage data-centric protection methods and Baffle’s solution to reduce your risk, unlock the value in the data and help to monetize it.

Baffle also supports headless deployments via Docker images. If you’d prefer to deploy via a Docker image and get up and running quickly. Please email support@baffle.io.

Shared Responsibility Model

Sample De-Identification of Data vs Clear Text

Baffle supports multiple database and file encryption modes including NIST certified and FIPS validated AES modes.

Attend this webinar to learn how data can be easily de-identified or tokenized as part of your data pipeline engineering. Learn how you can establish an S3 cloud data lake fully de-identified and use AWS Athena to easily access and run analytics on data sets for authorized users.
This session will provide a review of some key data security gaps related to a data analytics pipeline and provide a live demonstration of de-identified information on the fly during a migration, as well as subsequent data analysis via AWS Athena.
Data Protection Services
Enterprises continue to battle cybersecurity threats such as ransomware, as well as breaches and losses of their data assets in public and private clouds. New data management restrictions and considerations on how it must be protected have changed how data is stored, retrieved and analyzed.
Baffle’s aim is to render data breaches and data losses irrelevant by assuming that breaches will happen. We provide a last line of defense by ensuring that unprotected data is never available to an attacker. Our data protection solutions protect data as soon as it is produced and keep it protected even while it is being processed.
Baffle's transparent data security mesh for both on-premises and cloud data offers several data protection modes. Capabilities include:

Protect data on the fly as it moves from a source data store to a cloud database or object storage, ensuring safe consumption of sensitive data by downstream applications

De-identify and tokenize data using Format Preserving Encryption (FPE) or deterministic encryption modes

Data-centric protection at the field or record level in data stores secures the actual data values

Simplified dynamic data masking plus role-based access control to control who can see what data. Irreversible static masking to devalue data for test/dev environments or production clones

No-code field or row-level encryption in Postgres, MySQL, Snowflake, Amazon Redshift, Microsoft SQL Server, Kafka, and more

Encrypt files and de-identify data in cloud data lakes to enable AI and privacy-preserving analytics

Provides an off-the-shelf BYOK service for SaaS vendors to support multiple customer-owned keys in multi-tenant environments

REST API Data Protection Services
Easily deploy tokenization and data protection service for virtually any application or data store

Define which systems, users or groups can access data stores and dynamically entitle who can see what data

Run AI and ML algorithms against encrypted data without ever decrypting the underlying values. Baffle DPS supports any mathematical operation on encrypted data in memory and in process

Multi-party data sharing without compromising privacy. Allow multiple parties to submit data with a HYOK model and allow aggregate analytics to execute on co-mingled data stores

Enable secure sharing of data across multiple parties without revealing private values to other participants
Schedule a live demo with one of our solutions experts to get answers to your questions