Data sprawl: why application access controls as a security strategy doesn’t work
 October 10, 2023
October 10, 2023

As enterprises maintain more and more data, there is a greater need to ensure that sensitive data is protected. Privacy regulations are increasing which is fantastic for individuals who want to keep their data secure, but this places a burden on enterprises to know where data is stored and whether it is protected.
One of the more popular ways to address this need is application access controls, also known as privacy controls. This is where security or privacy rules are implemented in applications – one user group sees cleartext, another sees only masked data. This mostly works for simple use cases, such as the following example, where there are limited places the data lives:
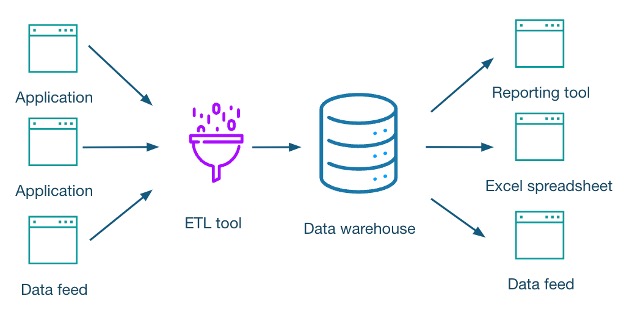
However this doesn’t address one of the biggest issues enterprises face: data sprawl. The above diagram is useful when discussing simple use cases, but most enterprises want to get as much business value out of their data as possible, which means building many data pipelines and getting data into the hands of a vast variety of stakeholders. A more typical example looks like this:
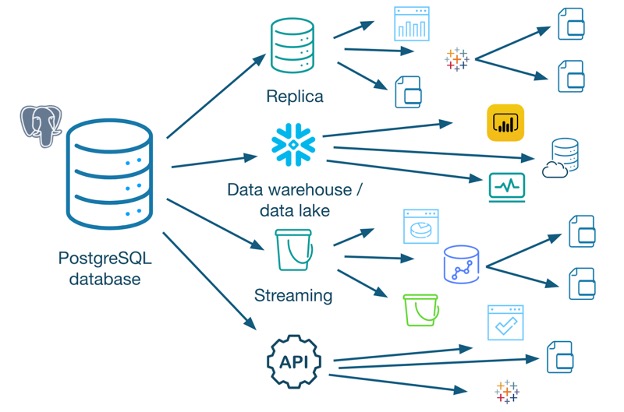
I like to think of data sources as prisms: there can be a thousand places where data flows from the source. Implementing application access controls can be an endless task – every time you add another application, it is going to be additional work to protect your data. Further complicating this, modern data teams use a variety of applications to get data out of their data sources – Tableau, PowerBI, SQL queries, APIs – which means different methods for protecting the data, depending on the source. The expenses for this can add up quickly and it prevents your organization from being able to respond quickly to changing business needs.
What is needed is data centric protection: protect data at its source and protect the data wherever it moves. Rather than play whack-a-mole and endlessly protect data every time you want to use it in a different way, protecting the data once in the data source is the most pragmatic approach to solving this problem.
Baffle Data Protection is a proxy-based model that provides data centric protection with no code or application changes required to protect data cryptographically everywhere it’s used. Baffle protects all data coming from the protected data source, so reports, spreadsheets, exported data sets, and SQL queries only show cleartext data to the users who have permission to access it. Baffle is easy and fast to implement, with a much lower total cost of ownership than application access controls.
Baffle is highly performant without the use of specialized hardware. Its high-performance architecture minimizes any performance impacts as well as any applications using the data. Baffle’s platform is flexible in that it protects data wherever it flows, giving you the ability to innovate no matter where the data is. Baffle is the solution to protecting data in a world where data sprawl is never-ending.
To learn more about Baffle Data Protection, contact us for a demo.




Join our newsletter
Schedule a Demo with the Baffle team
Meet with Baffle team to ask questions and find out how Baffle can protect your sensitive data.

Easy
No application code modification required

Fast
Deploy in hours not weeks

Comprehensive
One solution for masking, tokenization, and encryption

Secure
AES cryptographic protection

Flexible
No impact to user experience