Data Tokenization and Masking with Baffle in Amazon Redshift
 July 31, 2023
July 31, 2023

Amazon Redshift is a fully managed, cost-effective cloud data warehouse used by thousands of customers to analyze exabytes of data and run complex analytical queries. Redshift enables data analysis through SQL queries and existing business intelligence tools, allowing a much larger audience within your organization to extract valuable insights.
While opening countless opportunities, the democratization of all this data and analytics brings up a specific challenge: ensuring that sensitive data (PII, PCI, PHI) is protected. Customers, employees, and governments are demanding that their data remain secure and private.
Baffle Data Protection Services
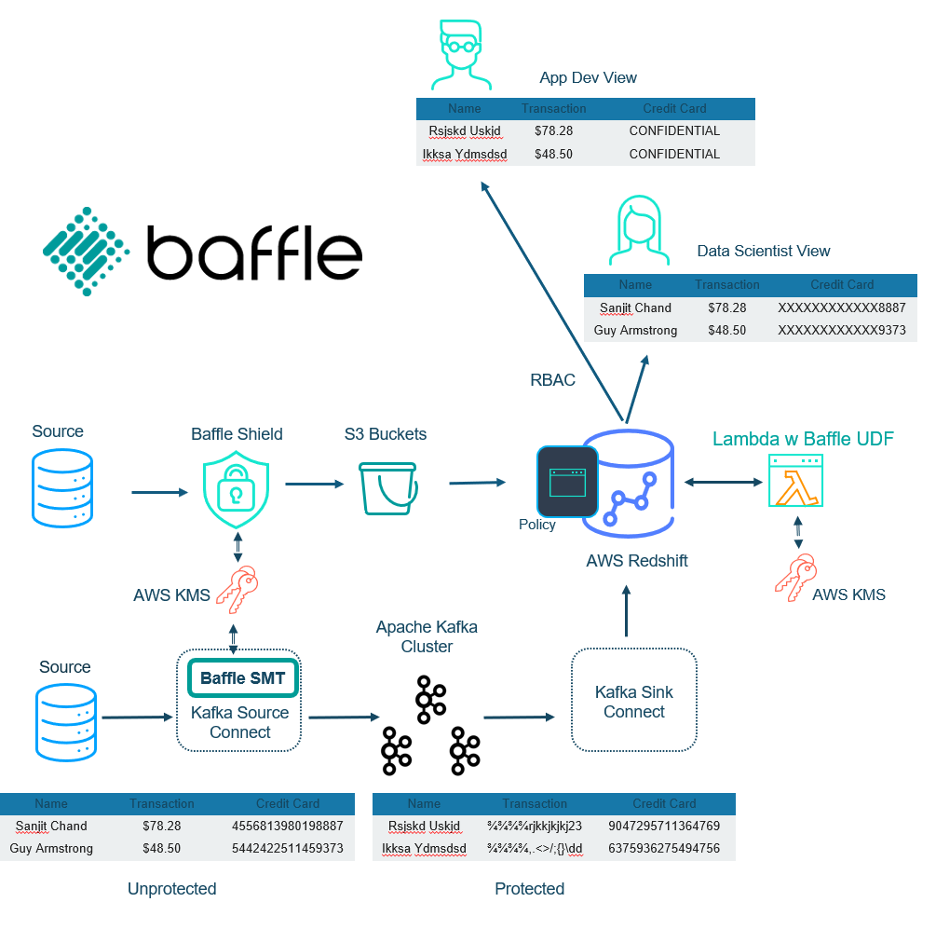
Baffle is an AWS Advanced Technology Partner that has collaborated with Amazon Redshift to provide tokenization and masking using Redshift’s Lambda UDF. The Redshift Lambda UDFs (user-defined functions) are managed by AWS and automatically scale to your Redshift implementation, ensuring security and performance. Organizations with strict requirements on protecting sensitive data can now apply the principles of least privilege without changes to their native software applications and continued use of third-party intelligence tools.
Using Baffle, Redshift SQL queries are masked or shown in the clear depending on the user’s role. Human Resources may be able to access a full social security number, while Support gets a masked version with only the last four digits in the clear (XXX-XX-1234). Marketing can access full names and contact information, while everybody else gets masked names and partially masked emails (joe@company.com becomes xxx@company.com).
An especially powerful aspect to Baffle’s approach: masking and tokenizing sensitive data doesn’t just occur when the data is queried, rather it is encrypted on ingestion, or at the sources. This protects the sensitive data during the entire data pipeline. The encryption may be traditional AES or the newer format-preserving encryption (FPE). FPE uses AES encryption with the process altered such that the data type and length of the plaintext is maintained. Infrastructure and applications can still process the FPE ciphertext without modification. Testing on credit cards can even be verified because the FPE ciphertext can pass the Luhn test. Despite the data being encrypted, SQL queries such as mathematical operation, sort, and search are still possible. FPE is a great way to implement tokenization without the headache of a separate look-up vault.
Baffle’s implementation works seamlessly with AWS KMS, so the customer has complete control of the keys. Baffle uses a two-tiered key approach where the customer managed keys encrypt data keys. The data keys are used to directly encrypt the data. It is one thing to allow the customer to control the keys, but key management is yet another issue. Baffle handles the key mapping, making the data transformation transparent to users and removing the management burden from the organization.
Baffle Solution and Architecture
Baffle Shield is a reverse proxy deployed as a container for data encryption on ingestion. The modular nature of Baffle Shield means that multiple instances can be deployed to enable multiple data sources. Not only that, but multiple Shields may be deployed per data source behind a load balancer or within a Kubernetes deployment to provide performance scaling and availability.
If Kafka is used, then Baffle provides an SMT (simple message transform) that enables encryption on ingestion. Baffle provides yet another option for file encryption (csv, JSON, XML fields, full-file) into S3 buckets (not shown in diagram).
On the consumption side, Baffle UDFs are deployed within AWS’s Lambda services. Users as defined by the application have corresponding roles and policies that determine the level of masking for respective SQL queries. These queries can even include mathematical operations, search, and/or sort results.
Performance
- firstname varchar(16)
- lastname varchar(16)
- email varchar(30)
- ssn varchar(11)
- ccn varchar(20)
- department(16)
Baffle performed tests consisting of two different queries. The first scenario uses the Lambda UDF to perform FPE on the payload and simulate actual usage. The second scenario also uses a Lambda UDF, but simply returns the payload as-is (echo) to simulate the total overhead such as network, i/o and other invocation overhead.
The query using FPE to detokenize is as follows:
select f_perf_fpe_string(firstname), f_perf_fpe_string(lastname), f_perf_fpe_string_email(email), f_perf_fpe_string_cc(ssn), f_perf_fpe_string_cc(creditcard), f_perf_fpe_string(department) from public.redshift_perf_1b_new;
The second query replaces “f_perf_fpe_string()” with “f_perf_echo_string()” so the Lambda functions are only selecting the data and not de-tokenizing it.
A Redshift cluster with 24 nodes of DC2.large machines. The Lambda function was instrumented with X-ray. The queries were iterated 10 times and the response times measured and averaged.

It turns out that the difference between tokenized and non-tokenized responses is negligible. Not readily apparent in this data is variance is dominated by the Lambda start-up time, which can range from almost nothing to over 400 ms for every query.
Conclusion
Baffle enables Amazon Redshift users to protect their sensitive data and meet their security and compliance needs. Data is encrypted at ingestion, allowing protection throughout the data pipeline at-rest, in-transit, and in-use. Tokenization and masking are done using role-based access control (RBAC) as determined by the applications. Baffle’s modular architecture enables maximum flexibility for many data sources, performant scaling, and availability. Perhaps, best of all, no application or infrastructure modifications are required to fit into your existing Redshift architecture.
Contact Baffle today



Join our newsletter
Schedule a Demo with the Baffle team
Meet with Baffle team to ask questions and find out how Baffle can protect your sensitive data.

Easy
No application code modification required

Fast
Deploy in hours not weeks

Comprehensive
One solution for masking, tokenization, and encryption

Secure
AES cryptographic protection

Flexible
No impact to user experience