
We recently announced our partnership with Snowflake (you can read more here), and are proud of our unique approach to data de-identification and privacy protection. This article and video cover how we’ve approached this integration to help quell fears of any re-identification risks, address privacy concerns, and accelerate customers’ move to Snowflake’s Data Cloud.
Baffle’s integration with Snowflake is the only solution that de-identifies data end-to-end in the data pipeline. One of the things that makes the solution unique is our ability to de-identify data on the fly as it moves to the cloud. Most people are trying to tackle this problem attempt to create clones and transform the data set or migrate the data set in the clear and then try to figure out how de-identify petabytes of data after it’s already landed in the cloud. Have you ever tried to tokenize or encrypt a petabyte of data?
At a simplistic level, our Data Protection Services for Snowflake performs two functions — (1) de-identification of data on the fly and (2) selective re-identification of data in Snowflake based on authorized roles. Below is a diagram that depicts a data pipeline flow where Baffle is de-identifying data before staging in S3 and re-identifying the data for Snowflake.
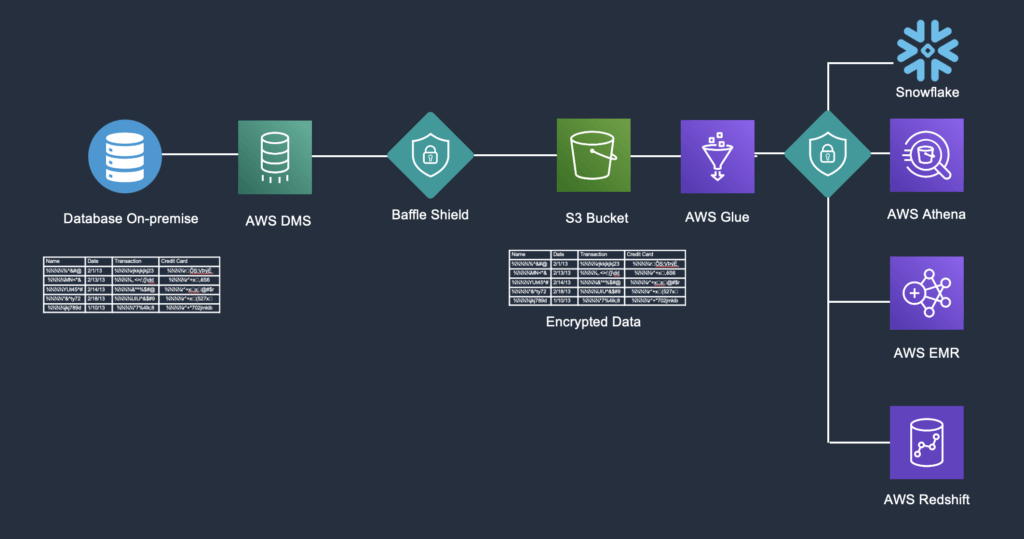
Let’s walk thru the data de-identification process into Snowflake.
The Flow Path
On-Premises Database – In this example, we have potentially sensitive data in the form of direct identifiers or personal identifiers such as credit card or social security numbers, date of birth, telephone numbers, biometric identifiers, protected health information based on HIPAA privacy rules, or even Internet Protocol (IP) address numbers saved in an on-premises database.
AWS DMS – The data will pass through Amazon Web Services Database Migration Service as the original data.
Baffle Shield – The data set will then hit the Baffle shield, where the data will be de-identified on-the-fly before being passed to the S3 bucket.
S3 Bucket – Data set lands here in the S3 bucket in a de-identified state ready for staging.
Snowflake – Data is piped into Snowflake, and here it can be used for analytics based on authorized roles. The de-identified information is in a format-preserving encryption mode keeping it safe.
Once the data from staging is copied to Snowflake, anyone attempting to view the data within an unauthorized role will only see the de-identified data. On the other hand, an authorized user running the same query will actually see data that is re-identified by Baffle on-the-fly.
Here aggregate operations can be performed. For example, a user can query the total sum of sales or a range-bound query of sales between 50 and 100. Or we can see the top 10 sellers in descending order. We can even execute a wildcard search on the data set within this environment.
This description and diagram may seem rudimentary, but it offers the ability to see how data elements can be moved to and from any source to any destination and have the data de-identified on the fly.
This 5-minute video below demonstrates how we do this on the fly.
With Baffle and Snowflake, you can move data to and from any source to any destination and de-identify it on the fly while allowing for analytics based on an authorized role.
You can learn more about our data de-identification capabilities here. Feel free to contact us at info@baffle.io if you’d like more information.
Learn about our supported encryption modes here.
Schedule a time to discuss your data pipeline security requirements with us here.
Download our white paper, “A Technical Overview of Baffle Hold Your Own Key (HYOK) and Record Level Encryption (RLE).”




Join our newsletter
Schedule a Demo with the Baffle team
Meet with Baffle team to ask questions and find out how Baffle can protect your sensitive data.

Easy
No application code modification required

Fast
Deploy in hours not weeks

Comprehensive
One solution for masking, tokenization, and encryption

Secure
AES cryptographic protection

Flexible
No impact to user experience