

IBM Cloud offers an extensive portfolio of cloud-native databases that IBM provides as secure, production ready, and fully managed database technologies, to enable developers to spend less time running databases and more time building business value. Our breadth of commercial and open source databases, that we run as service, can support any data use cases you bring to IBM Cloud: structured, unstructured, event, IoT, blockchain, and analytics.
With data moving to the cloud, data privacy requirements have gotten more challenging especially in the light of new attack vectors. Traditionally, on-premises databases have required database administrators to have root level access to systems as well as unrestricted access to the data itself. Those were the days when you could trust anything that was on your network.
As computing architectures have evolved, threats have increased in sophistication, and compliance mandates have gotten stricter we have entered a new era of zero trust. Legacy features such as transparent data encryption (TDE) no longer offer adequate protection against attack vectors such as account takeovers, lateral movement, and insider threat. To further complicate matters, business drivers increasingly require real-time sharing of data with partners and the supply chain. Even internally, as data analytics applications have exploded so have the number of database clones for various development and testing use cases.
Clearly a modern solution for effective and scalable data protection is required. This is where IBM Cloud in conjunction with Baffle Data Protection Services steps in to deliver modernized data protection. The primary benefits are:
- On-the-fly de-identification of data as it is moved to the cloud
- “No code” easy deployment that does not require application changes
- Fast, scalable, and highly performant
- Role-based data access control to dynamically enforce who can see what data
- Consolidated suite of data protection capabilities such as encryption, tokenization, dynamic data masking, Format Preserving Encryption (FPE), field and record level encryption, file and object encryption, secure data sharing, Privacy-Enhanced Computation (PEC), and more
- Bring Your Own Key (BYOK) and Keep Your Own Key (KYOK) for customer owned keys in multi-tenant Cloud environments
- Safe harbor from accidental data leaks for privacy and compliance regulations
In this post we outline how to marry stringent data privacy requirements with bringing workloads to a cloud database-as-a-service offering. Hypothetically, let’s say your business has decided to focus on adopting PostgreSQL, a popular open-source RDBMS, for business modernization migrations from on-premises.
IBM Cloud offers two variants of fully managed PostgreSQL, IBM Cloud Databases for PostgreSQL and IBM Cloud HyperProtect DBaaS for PostgreSQL. Both offerings provide the alluring features of database-as-a-service, such as compliance certifications, automatic backups, high availability, bring your own encryption key, and database/operating system patching. However there is a key difference between the two offerings, and that is one of server-side technical assurance capabilities for data security.
HyperProtect DBaaS, built on IBM Z/LinuxONE ‘s confidential computing technology, provides workload isolation, restricted administrator access and tamper protection for data at rest, data in use and in flight. Not even the cloud administrator has access to your data at any point.
Regardless of the PostgreSQL offering you choose to use in IBM Cloud, for sensitive data requirements especially the ones like Personally Identifiable Information (PII) data, we have seen enterprises want to ensure those data are tokenized or encrypted at application layer so that it gets tokenized or encrypted even before it gets stored in the database. Based on such requirements to mitigate risk, we recommend adopting client-side encryption of data before it’s stored in a database. IBM and Baffle have now partnered together to offer Baffle Data Protection Services on IBM Cloud, enabling developers and DBAs to easily set up a no-code change integration for client-side encryption with Databases for PostgreSQL and HyperProtect DBaaS for PostgreSQL.
Baffle Data Protection Services (DPS) for IBM Cloud provides a data-centric protection layer allowing customers to tokenize, encrypt, and mask data at the column or row level, without any application code modifications while supporting a BYOK or KYOK model.
Let’s review the architecture for Baffle DPS and how it performs its tokenization and masking functions.
Overview of Solution Components
Baffle DPS consists of three major components:
- Baffle Manager – Administrative console for configuration and management of data protection policies.
- Baffle Shield – TCP protocol reverse proxy that performs encryption, decryption, tokenization, masking, and access control functions.
- Key Virtualization Layer – Interface layer for generating and retrieving encryption keys from key management stores and secrets vaults via industry standard protocols.
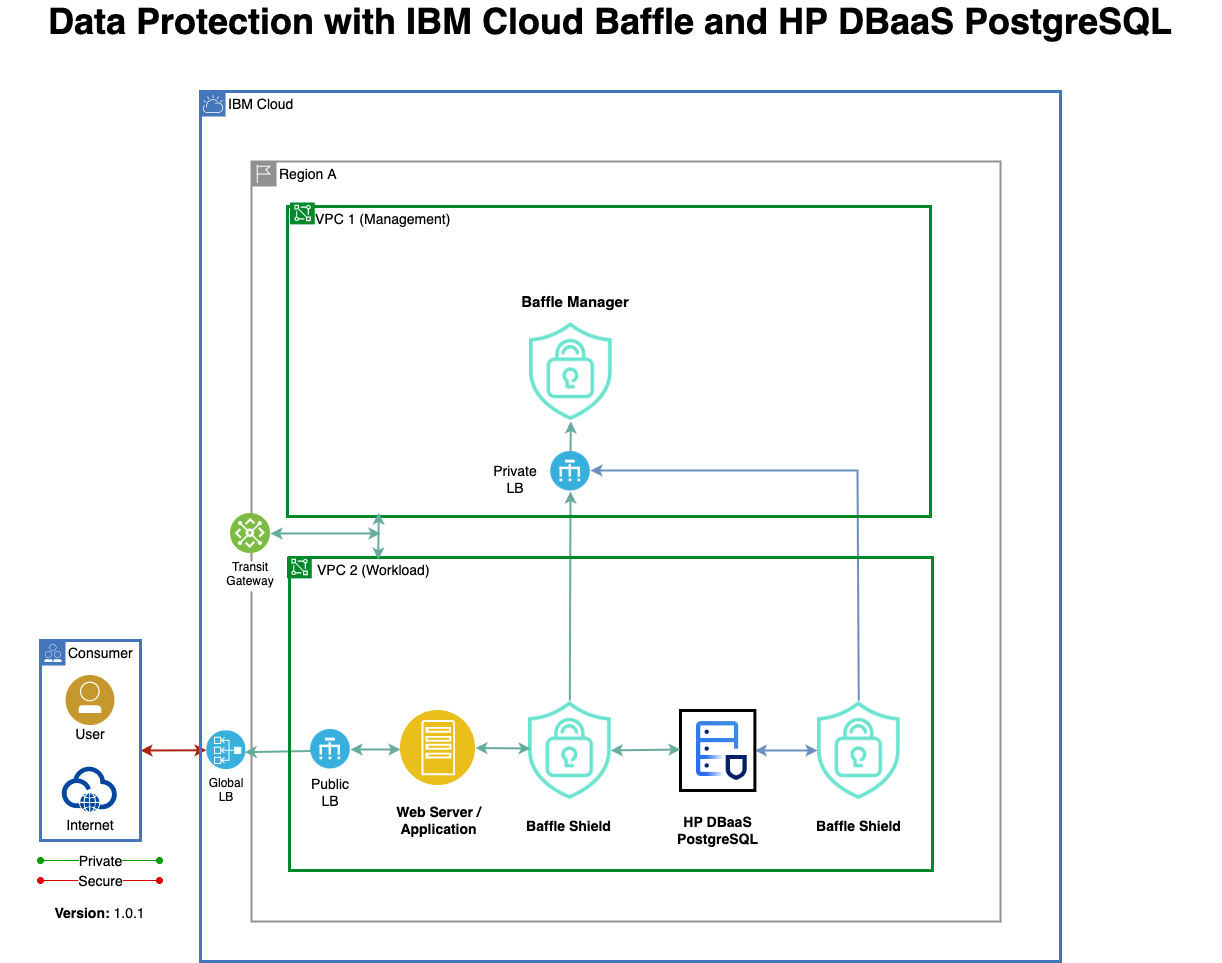
Baffle DPS can also run in a headless mode for tighter integration with CI/CD pipelines for DevOps-oriented deployments.
How it Works
Normally, applications establish a connection to a database via a database client and driver. With the Baffle Shield, a transparent data protection layer is established in front of an IBM Cloud database instance that the application tier (clients, microservices, API calls) connects to instead of a direct connection to the database instance.
This transparent layer presents the original data schema to the application tier so any tokenization or masking operation is, effectively, invisible to the client.
Baffle Shield can be deployed via IBM Cloud Compute instances, Docker images, Kubernetes pods (IBM Catalog offering) and OpenShift Pods.
For high availability, the solution can run behind IBM Cloud Load Balancers with auto scale instance groups. Alternatively, Kubernetes pods can be used to instantiate instances of Baffle Shield with scaling and redundancy policies.
Once instances are running, traffic is routed through the Baffle Shield via a connection string update that points to the Baffle Shield IP address or hostname. Application traffic continues to authenticate against the database and connections access any cleartext data at wire speed.
To perform tokenization or encryption of data, the Baffle Manager is used to define a data protection policy to create a privacy schema and maps database columns to a given encryption key and protection mode.
This mapping gets propagated to the Baffle Shield, which performs data encryption and decryption for a given column based on the privacy schema. This provides the Baffle Shield with knowledge of encrypted or tokenized columns while always presenting the original data schema to the application tier.
Baffle supports the following data protection modes for IBM databases:
- NIST standard AES-256 encryption for field or row-level protection
- Format Preserving Encryption (FPE) tokenization
- Dynamic Data Masking
- Role-Based Data Masking
Key management integration is performed via a key virtualization layer. Baffle DPS’s key virtualization layer supports industry standard protocols such as Key Management Interoperability Protocol (KMIP) 1.1 and higher, PKCS #11, and REST to integrate with enterprise key management solutions, hardware security modules (HSMs) and cloud key vaults.
This integration layer allows customers to encrypt data in IBM Cloud while enabling a BYOK or KYOK model. It can integrate with IBM Cloud Key Protect supporting BYOK or with IBM Cloud Hyper Protect Crypto Services supporting KYOK. With the KYOK model and Baffle, clients can achieved technical assurance that they completely control the data at application layer with client side encryption, and that they have fully authority over the keys with the unique KYOK technology in IBM Cloud.
To learn how to deploy and configure Baffle Data Protection Services for IBM Cloud, check out the step by step instructions.




Join our newsletter
Schedule a Demo with the Baffle team
Meet with Baffle team to ask questions and find out how Baffle can protect your sensitive data.

Easy
No application code modification required

Fast
Deploy in hours not weeks

Comprehensive
One solution for masking, tokenization, and encryption

Secure
AES cryptographic protection

Flexible
No impact to user experience