
This blog, the third in a series on “Why you can’t stop data breaches”, details various attack methods used to compromise a set of common data tokenization methods. The first entry in the series discussed database level encryption, encryption at-rest and gaps in the threat model and is linked here. The second post covers common approaches to data tokenization and how these methods lack a secure approach.
According to a report from Risk Based Security, over 7.9 billion data records were exposed in 2019.
One of the fundamental reasons data breaches and leaks continue to happen ad nauseam is because the data itself remains unprotected. That may sound like an obvious statement, but in this post, we walk through a threat model analysis of modern day data access patterns and highlight how you can mitigate some key risks to your data.
Several elements contribute to how and why data continues to be exposed or stolen, but a major factor continues to be a lack of understanding of the complete threat model for your data. And more specifically, how this threat model and mitigation strategies can be applied to cloud data protection.

A Security Analysis Of Data Tokenization Systems
We can start by looking at how data gets accessed in a typical application deployment. This diagram below shows a simplistic view of data access.

Simple application and data access architecture
We have users, an application tier, and a database. Pretty basic, but we can look at some of the challenges in securing data here at each point in this architecture. From a user perspective, (in an overly simplified analysis) you have “good users”, “bad users”, “unknown users”, and “compromised users”. These users are accessing the data through an application tier, where you have deployed or are running a “good application”, “bad application”, or “malicious application”. And ultimately, the data is being requested by “legitimate data requests”, “excessive data access”, “privileged users and insiders”, or “coercive data access”.
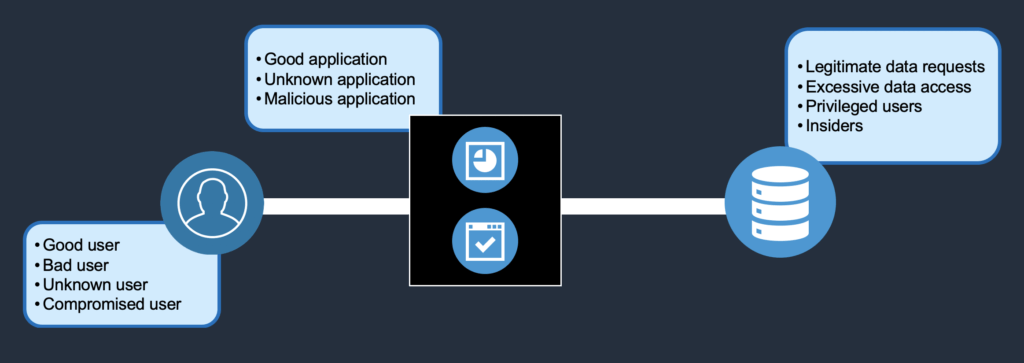
Legitimate vs. Unauthorized Data Access
Let’s look at how we can secure this data through data access governance strategies. We can utilize database encryption. Here’s what your data looks like with database encryption or data-at-rest encryption enabled. Any attacker moving laterally in the network or compromising the app tier will see your data as it is below.
At-rest and database encryption leave your data in the clear
All locked down and secured, right? That’s a common misconception that we discuss in more detail here and it is worth understanding the different risks that are mitigated by specific data protection strategies. But, of course, there are other methods that we can use to secure the data.
For users, there are identity access management (IAM) and user behavioral analysis (UBA) solutions along with multi-factor authentication (MFA). At the application tier, we have workload protection security, web application firewalls (WAF), code analysis and profiling. And at the data tier, we have data access monitoring (DAM), privileged access management (PAM) and encryption.
So, after you’ve spent a good deal of time, money and resources and implemented all of the above, your environment is secure, right? It’s a siloed approach at each tier, but relatively secure. Well, the above architecture is pretty simplistic, so let’s make it more complex.
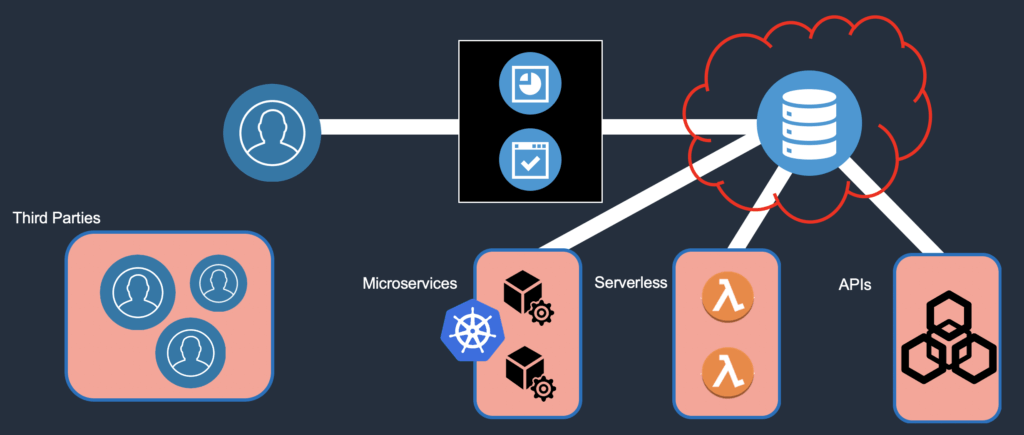
A more complex view of data access models
We decide to onboard multiple third parties to help us process our data, support our customers, and optimize our operations, so our user base becomes more distributed (we could also add in impact of the global pandemic on user distribution). Our application infrastructure is n-tier, container-based microservices and serverless code functions with API access enabled. And we throw the database and data lake in the cloud to boot.
The net result is our user base has expanded and is beyond our immediate organizational control. The application footprint is now code (“good code”, “malicious code”) and workload based and more distributed. And we’ve added an untrusted environment to house the actual data.
Whether you subscribe to the simple world or the complex one depicted above, and whether you buy into the “zero trust” hype or not, the threat model for data access in its entirety, suggests that attackers will get at your data. And if you do not take data-centric protection measures, the data will be accessed in the clear, and that is why breaches continue to occur.
The transition to more data accessible all the time (which is the world we live in) mandates a data protection strategy that can keep up. Implementing adaptive data security methods can help better secure your data access channel from “some” user using “some code” and requesting “some data”. The approach entails implementing a common data protection service architectural model that transparently protects your data and simultaneously controls access.
Learn more about how you can stop data breaches via our data protection services.




Join our newsletter
Schedule a Demo with the Baffle team
Meet with Baffle team to ask questions and find out how Baffle can protect your sensitive data.

Easy
No application code modification required

Fast
Deploy in hours not weeks

Comprehensive
One solution for masking, tokenization, and encryption

Secure
AES cryptographic protection

Flexible
No impact to user experience